Procesos, concurrencia y paralelismo
Table of Contents
En este apartado vamos a estudiar un concepto fundamental en la programación que es la abstracción que hacen los sistemas operativos de las unidades de ejecución: los procesos.
Estos nos dará pie a introducir conceptos, muy importantes, como son la concurrencia y el paralelismo.
Procesos
Como ya sabrás a estas alturas, los programadores escriben programas con lenguajes de alto nivel que el ordenador no puede ejecutar. El código fuente de estos lenguajes tiene que ser traducido a lenguaje máquina y convertido en un ejecutable.
Un fichero ejecutable es aquel que tiene un formato determinado que el Sistema Operativo reconoce y puede cargar en la memoria para empezar su ejecución.
En Linux los ficheros ejecutables tienen formato ELF y en Windows formato PE (Portable Executable), por poner dos ejemplos.
Entendido esto, un proceso, informalmente, no es más que un programa en ejecución. Así que, cuando el Sistema Operativo carga el programa ejecutable en memoria y da comienzo su ejecución, a partir de este momento, ya lo podemos llamar proceso.
Los procesos están bajo el control del Sistema Operativo que será el encargado de proporcionar los recursos que necesita: otorgar tiempo de ejecucion en la CPU, proporcionar recursos como memoria y almacenamiento secundario, acceso a los periféricos, etc.
Gestión de procesos por el Sistema Operativo
El Sistema Operativo (a partir de ahora SO) gestiona los procesos por medio de lo que se conoce como planificador de procesos. Este planificador es el encargado de ofrecer tiempo de ejecución a cada proceso, para lo cual necesita mantener una estructura de procesos en la que por cada proceso se almacena:
- Un PID: cada proceso tiene un Process IDentifier o PID que lo identifica de forma única.
- Un espacio de direcciones de memoria y lista de ubicaciones que va desde un mínimo a un máximo donde el proceso puede leer y/o escribir datos en memoria.
- El contenido de los resitros de la CPU para que cuando se vuelva a otorgar tiempo de ejecución se pueda restaurar el estado en que se encontraba la CPU en el momento en que se cambió por otro proceso.
- Otros recursos como ficheros que tiene abiertos, "relaciones" con otros procesos, estadísticas de uso de CPU, recursos de Entrada/Salida ocupados, estado en que se encuentra, etc.
A continuación te muestro la parte de un programa que podría ser parte del planificador de procesos de un SO:
public class Proceso { private int pid; private int memoriaMinima; // Dirección mínima de memoria private int memoriaMaxima; // Dirección máxima de memoria private String estado; private String[] registrosCPU; // Contenidos de los registros de la CPU private String[] recursosAbiertos; // Recursos abiertos por el proceso public Proceso(int pid, int memoriaMinima, int memoriaMaxima) { this.pid = pid; this.memoriaMinima = memoriaMinima; this.memoriaMaxima = memoriaMaxima; this.estado = "Creado"; this.registrosCPU = new String[10]; // Suponemos que la CPU tiene 10 registros this.recursosAbiertos = new String[5]; // Suponemos que el proceso tiene 5 recursos abiertos } // Resto del código... }
El código está en Java porque es el lenguaje con el que estás familiarizado pero los Sistemas Operativos están escritos en lenguajes de bajo nivel como C.
Espacio de direcciones de un proceso
Cuando hablamos del espacio de direcciones de un proceso nos referimos al conjunto de posiciones de memoria que el proceso puede utilizar durante su ejecución. Es el SO el que se encarga de asignar y administrar esa memoria. Aunque para entenderlo no es estrictamente necesario, conviene recordar que dichas direcciones no son físicas, sino virtuales, ya que el hardware y el SO se encargan de mapearlas a direcciones reales en la RAM.
Dentro de este espacio, la memoria de un proceso suele dividirse en varias secciones principales:
.textcontiene las instrucciones del programa, es decir, el código ejecutable en lenguaje máquina..dataalmacena las variables globales y estáticas inicializadas del programa..rodataguarda los datos de solo lectura, como constantes literales que no cambian durante la ejecución.
Además de estas, en la práctica existen otras regiones relevantes:
.bssse reserva para variables globales y estáticas no inicializadas (el SO las rellena con ceros al inicio).heapespacio dinámico que crece hacia direcciones altas, utilizado para memoria asignada en tiempo de ejecución (por ejemplo, conmallocen C onewen C++).stackmemoria para las variables locales y el contexto de ejecución de las funciones (parámetros, direcciones de retorno, etc), que crece hacia direcciones bajas.
Esta organización permite al sistema operativo gestionar de manera eficiente la memoria, aislar procesos entre sí y ofrecer mecanismos como protección de escritura/lectura o memoria compartida.

Figure 1: Varios procesos en la memoria
Estados de un proceso
En un ordenador existen muchos procesos en ejecución al mismo tiempo. A esto se le conoce como computación concurrente: varios procesos ejecutándose al mismo tiempo.
El planificador de procesos del SO aplica ciertos algoritmos para permitir que varios procesos puedan usar la misma CPU o recursos, otorgando tiempo a todos los procesos sobre estos recursos, y moviendo a todos estos procesos a través de una maquinaria de estados. Los estados en que se puede encontrar un proceso son:
- Creado: primero el proceso es creado, cargando sus instrucciones y datos del disco secundario a la memoria principal. A continuación es llevado al estado Esperando.
- Esperando: en este estado, el proceso espera a que el planificador lo elija para hacer el cambio de contexto, es decir, le asigne la CPU para ser ejecutado y, por tanto, pase al estado de Ejecución.
- Ejecución: por cada core que tenga la CPU puede haber un proceso en este estado. Aquí se ejecutan las instrucciones del proceso. El planificador del SO irá alternando a los procesos para que todos tengan tiempo de ejecución. Si el SO hace un cambio de contexto, el proceso que se está ejecutando pasará al estado de Esperando. Además, puede pasar que el proceso necesite algún recurso (por ejemplo, necesita abrir un fichero o iniciar comunicación por la red) y pasaría al estado de Bloqueado, llevando a cabo un cambio de contexto.
- Bloqueado: aquí se encuentran los proceso en espera de un recurso. Cuando lo tenga disponible pasará al estado de Esperando para que el planificador lo pueda seleccionar para ser ejecutado de nuevo.
- Terminado: una vez se han ejecutado todas las instrucciones de un proceso, el planificador lo pasa a este estado. Aquí, el proceso, espera a ser eliminado y quitado de la memoria, dejando dicho espacio de memoria libre.
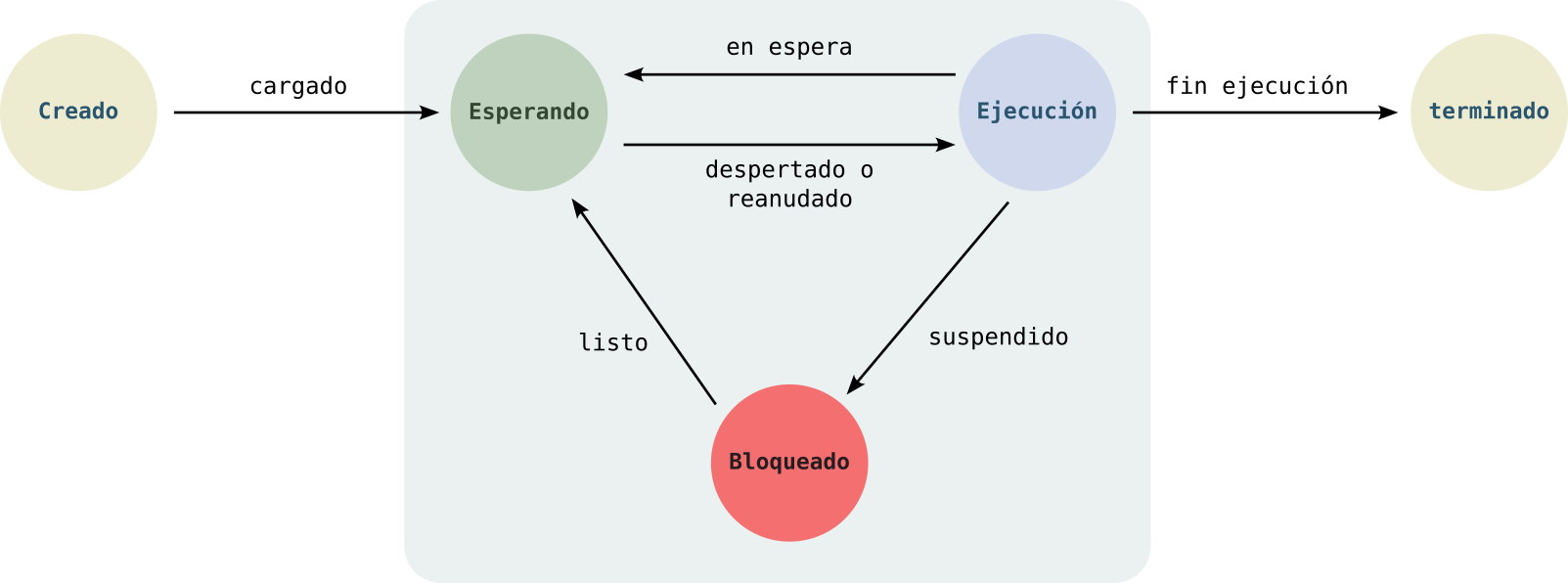
Figure 2: Estados de un proceso
En esta maquinaria de estados vemos como el planificador va durmiendo y despertando procesos para alternarlos entre los estados de Ejecución y Esperando. Además, cuando un proceso necesita un recurso de Entrada/Salida (por ejemplo, abrir un fichero) es suspendido y pasa al estado de Bloqueado. Una vez está el recurso de Entrada/Salida listo es devuelto al estado de Esperando.
El planificador de procesos solo elige a los procesos que están en el estado Esperando para pasar a ser ejecutados por la CPU, cambiándolos al estado de Ejecución.
A los cambios entre los estados Esperando <–> Ejecución se le denomina cambio de contexto.
Subprocesos
Al principio se explicó y se dio la definición de proceso: un programa en ejecución. Siendo real, no es del todo preciso porque un proceso puede crear otros procesos, a los que, a veces, se les llama subprocesos.
Así pues, se puede dar el caso en que un programador escribe un programa que compila y lo convierte en ejecutable, y ese único programa ejecutable podría crear varios procesos. Así pues tendríamos: un programa y varios procesos.
A esta técnica se la conoce como programación multiproceso. Y, ¿por qué existe esta técnica? Para optimizar los recursos computacionales y mejorar tiempos de ejecución. Dado que, hoy en día, todo el mundo usa ordenadores con varios procesadores o CPUs, podemos (debemos) aprovechar esta capacidad escribiendo programas que creen varios procesos.
Dicho así resulta sencillo pero, en realidad, durante el desarrollo de un programa tenemos que decidir cuándo crear varios procesos para explotar la capacidad computacional de los ordenadores. Aquí te enumero algunos motivos por los que no es tan fácil:
- Los procesos realizan tareas que, a veces, se tienen que dar en una determinada secuencia.
- Puede ser necesario que haya comunicación entre los procesos.
- Suele ser habitual la necesidad de sincronización entre los procesos.
Jerarquía de procesos
Cuando se emplea la programación multiproceso se tiene una jerarquía de procesos en los que hay padres e hijos.
El caso de Linux es un ejemplo claro: cuando arranca el SO Linux se crea un proceso llamado init que es el proceso padre de todos los demás.
Cuando abres un programa lo hace este proceso init. Además, el proceso creado por init podría crear otros procesos que a su vez pueden crear otros procesos, generando dicha jerarquía de procesos.
En la siguiente imagen se puede ver una captura de imagen de la salida del comando pstree -u de GNU/Linux, en la que se muestra una representación de los procesos que se están ejecutando ahora mismo, mientras escribo estas líneas, en mi ordenador:
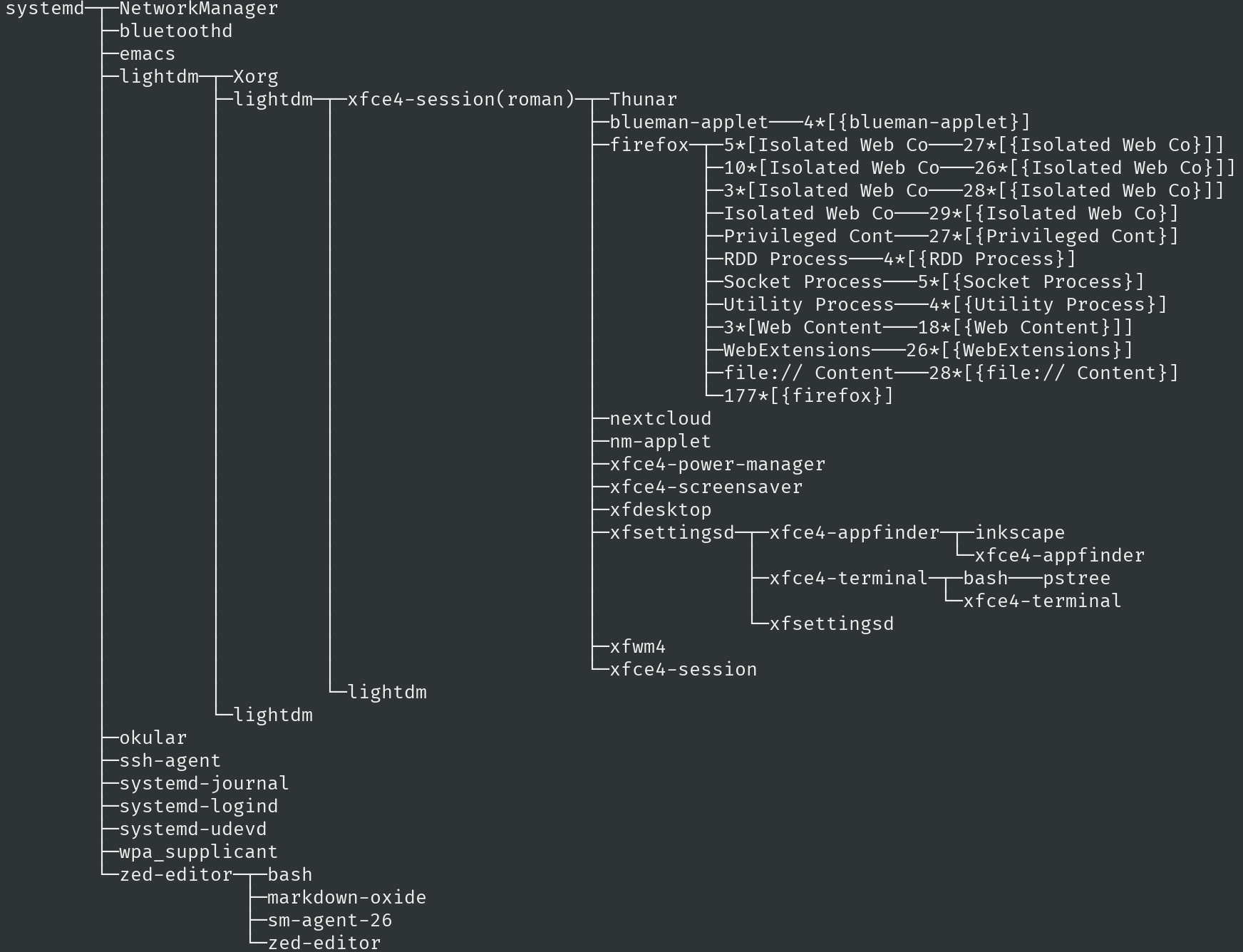
Figure 3: Salida del comando pstree -u
Como ves en la captura, el primer proceso, el padre de todos, se llama systemd (el proceso init). A partir de ahí se han ido creando todos los demás.
Representativo es el caso del proceso firefox (el navegador web) donde, como ves, ha creado varios procesos: un solo programa y 12 procesos.
Concurrencia y paralelismo
Es muy importante diferenciar entre estos dos conceptos que, a veces, es difícil de diferenciar.
Dos acciones o tareas son concurrentes si se ejecutan de forma alterna en el mismo tiempo. Dichas tareas se están superponiendo durante el mismo tiempo.
Dos acciones o tareas son paralelas si se ejecutan al mismo tiempo, simultáneamente. Esto, en computación, requiere de varias CPU.
Para que haya paralelismo se necesita concurrencia. Dicho de otro modo: no puede haber paralelismo si no hay concurrencia.
Veamos, en los siguientes apartados, los detalles de la programacion concurrente, paralela y distribuida (que es una forma de paralelismo).
Programación concurrente
La computación concurrente es la que permite que varias tareas se puedan ejecutar durante el mismo periodo de tiempo. La programación concurrente es la técnica de programación que permite crear sistemas donde varios procesos se puedan ejecutar al mismo tiempo.
Hay que llevar cuidado con este concepto porque se suele confundir con computación o programación paralela, las cuales están relacionadas pero son diferente como se verá más adelante.
Te explico con un ejemplo en qué consiste la computacion concurrente y cómo funciona, aunque en el apartado anterior ya se ha hecho de forma implícita. Imagina un sistema en el que hay tres procesos ejecutándose durante el mismo tiempo, es decir, concurrentemente. Estos tres procesos son A, B y C. No obstante, solo hay una CPU, por lo que solo un proceso puede ejecutarse en la CPU en un instante dado. El planificador del SO decidirá en cada momento qué proceso se ejecuta en dicha CPU. Este podría ser el diagrama temporal de ejecución de los procesos A, B y C:
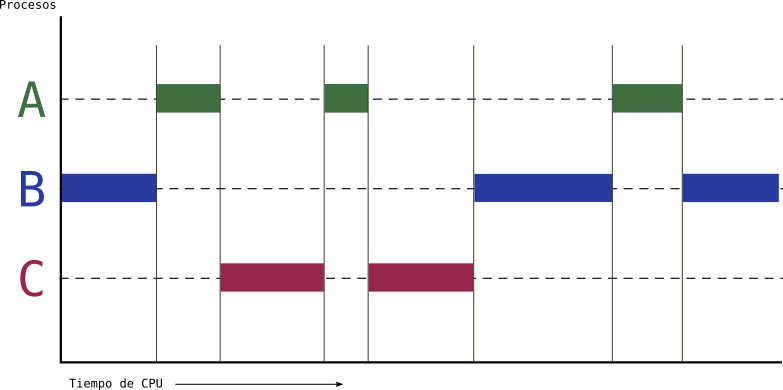
Figure 4: Computación concurrente de tres procesos: A, B y C
Como se aprecia en el gráfico hay tres procesos en ejecución al mismo tiempo (concurrentemente) pero no hay paralelismo porque en cada instante solo un proceso está siento ejecutado por la CPU.
Programación paralela
Para que haya computación paralela es necesario que exista computación concurrente. La diferencia está en que los procesos se pueden ejecutar en paralelo porque, por ejemplo, hay varias CPU. La programación paralela es la técnica a través de la cual se explota la presencia de varias CPU para dividir el trabajo entre ellas, acortando el tiempo de ejecución.
Con el siguiente diagrama debería quedar clara la diferencia entre concurrencia y paralelismo. En el escenario representado por este diagrama existen dos CPU: CPU1 y CPU2, por eso se pueden ejecutar hasta dos procesos juntos:
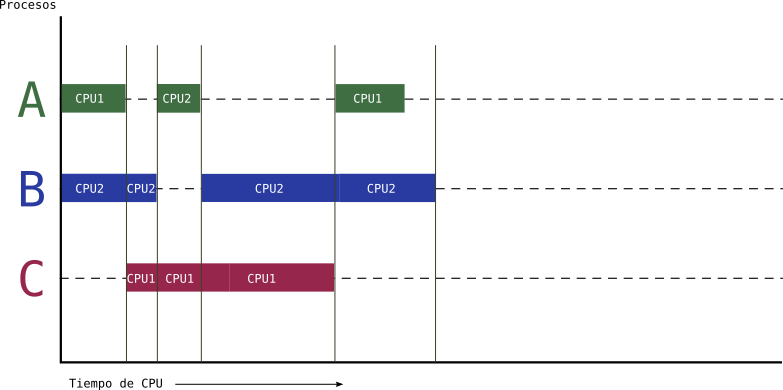
Figure 5: Computación paralela de tres procesos en dos CPU: A, B y C
En la imagen se pueden ver los tres procesos anteriores y cómo se van ejecutando en la CPU1 y la CPU2 en función de las necesidades. Verás, que el tiempo total de ejecución se ha acortado bastante. La computación paralela permite acortar tiempos de ejecución totales aunque la gestión del planificador se complica.
Programación distribuida
La computación distributida es aquella en la que hay varios ordenadores conectados en red donde se distribuyen las tareas o procesos, consiguiendo así el paralelismo explicado anteriormente. La programación distributida, por tanto, es la técnica en la que se escriben programas que trabajan coordinadamente en esta red de ordenadores distribuidos.
En realidad, es un tipo de computacion paralela en la que se emplean varios ordenadores en vez de varias CPU en un mismo ordenador.
No obstante, cuando hablemos de computación paralela nos referiremos a un único ordenador con varias CPU y cuando hablemos de computación distributida nos referiremos a varios ordenadores conectados por red para repartir el trabajo o los procesos.
Sistemas síncronos y asíncronos
Por último, dos conceptos relacionados con la concurrencia es el de sincronía y asincronía.
Dos tareas son síncronas si el orden en que se tienen que ejecutar es importante, es decir, es crucial el orden para el resultado final.
Por contra, si dos tareas se pueden ejecutar en cualquier orden, porque el resultado final no varía, entonces estas serían asíncronas.
Un par de ejemplos mundanos para aclarar estos conceptos:
- Imagina un proceso de fabricación en una línea de ensamblaje de automóviles. Un operario no puede instalar las puertas de un vehículo hasta que el operario anterior haya completado la instalación del chasis. Aquí, el orden de las tareas es fundamental para asegurar que el producto final sea seguro y funcional.
- Considera un sistema de procesamiento de pedidos en un restaurante. Un cliente puede hacer un pedido de comida, mientras que otro puede solicitar una bebida. La preparación de la comida y la bebida puede llevarse a cabo simultáneamente y en cualquier orden, ya que no dependen una de la otra para ser servidas. Esto permite que el restaurante atienda a más clientes de manera eficiente.
Estos conceptos se realicionan con la concurrencia y el paralelismo porque las tareas asíncronas se pueden explotar de forma parelala acelerando los procesos.