Hilos en Python
Table of Contents
Python proporciona concurrencia por medio de hilos a través del módulo threading (Python Threading). Este permite manejar y gestionar hilos, haciendo posible la ejecución paralela de tareas compartiendo el espacio de memoria.
Recuerda que los hilos de un mismo proceso comparten el espacio de memoria.
Los hilos son particularmente útiles para tareas de de E/S (Entrada/Salida), como son operaciones con ficheros y peticiones por red, donde gran parte del tiempo se gasta esperando recursos externos.
Procesos vs Hilos
Recuerda, del tema anterior, que los procesos y los hilos están relacionados. De hecho, un hilo es parte de un proceso, ya que es una unidad de ejecución de un proceso. Un proceso tiene, siempre, un hilo inicial llamado hilo principal. A partir de aquí, los procesos, pueden crear más hilos que ejecuten tareas concretas explotando, así, las capacidades de concurrencia y paralelismo de los sistemas actuales.
Ciclo de vida de un hilo
- Nuevo hilo, un hilo creado con
threading.Thread - Hilo en ejecución, que puede bloquearse y pasar al estado de hilo bloqueado
- Hilo terminado
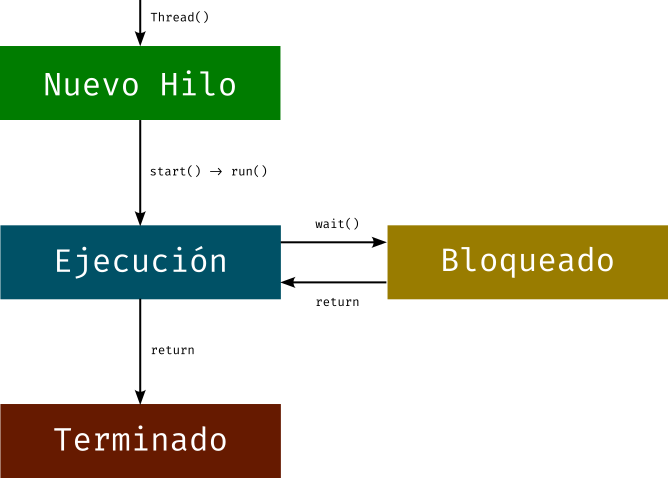
Figure 1: Estados de un hilo
Hilos en Python
Dentro del módulo threading tenemos una clase para crear y manejar hilos en Python: Thread. Esta clase se usa de forma similar a la clase Process del módulo multiprocessing estudiado en el tema anterior. Así, son APIs homogéneas que hace sencillo usar ambas opciones.
Uso básico de hilos:
- Crea un hilo:
from threading import Thread import time def f(delay): time.sleep(delay) thread = Thread(target=f, args(3,))
- Ejecútalo:
thread.start()
- Espera a que el hilo finalice:
thread.join()
Ejemplos básicos
Ejecución de una función en un hilo
Veamos el ejemplo básico que encontramos en la documentación oficial de Python, introducción a los hilos en Python, en el que tenemos:
- Una lista de enlaces sobre las que vamos a simular un crawler (función
crawl) - Por cada enlace se crea un hilo que hará el scraping de dicho enlace
- Como en el caso de los programas multiproceso, se lanzan los hilos con el método
start()y se espera a que finalicen con el métodojoin()
import threading import time links = [ "https://python.org", "https://docs.python.org", "https://peps.python.org", ] def crawl(link, delay=3): print(f"crawl started for {link}") time.sleep(delay) # Blocking I/O (simulando petición por red) print(f"crawl ended for {link}") # Se crea un hilo por cada enlace (link) threads = [] for link in links: t = threading.Thread(target=crawl, args=(link, 2)) threads.append(t) # Se da comienzo a todos los hilos anteriormente creados for t in threads: t.start() # Esperamos que finalicen todos los hilos for t in threads: t.join()
Extendiendo la clase Thread
Como en el caso de los procesos, con los hilos también puedes crear tu propia clase que herede de Thread y sobreescriba el método run() que es el método que se ejecutará cuando se llame el método start() del hilo creado.
Para entenderlo, aquí tienes el ejemplo anterior usando una clase derivada de Thread:
import threading import time class WebCrawler(threading.Thread): def __init__(self, link, delay): super().__init__() self.__link = link self.__delay = delay def run(self): print(f"crawl started for {self.__link}") time.sleep(self.__delay) # Simulando petición por red print(f"crawl ended for {self.__link}") if __name__ == "__main__": links = [ "https://python.org", "https://docs.python.org", "https://peps.python.org", ] threads = [] for link in links: t = WebCrawler(link=link, delay=2) threads.append(t) for t in threads: t.start() for t in threads: t.join()
Métodos, atributos y utilidades de la clase Thread
Existen métodos y atributos de la clase Thread que puedes usar en tus programas y que resultarán útiles en diferentes contextos. Como siempre, en la documentación oficial tienes todos los detalles, aquí te resumo y destaco solo parte de lo que te proporciona la clase Thread.
Para todos estos ejemplos vamos a suponer que hemos creado un hilo llamado thread:
thread.ident: cada hilo tiene un identificador que le asigna el intérprete de Python y que está en la propiedadident.thread.native_id: la propiedadnative_idcontiene el identificador del hilo que le asigna el sistema operativo (identificador nativo del hilo).thread.is_alive(): el métodois_alive()devuelveTruesi el hilo está activo (en ejecución) oFalsesi está dead (terminó su ejecución).thread.name: los hilos tienen un nombre y este nombre se puede asignar al construir el hilo, por ejemplo, el siguiente código crea un hilo y le asigna un nombre de forma explícita vía argumento:
thread = Thread(name="Mi hilo", target=func)
A continuación, se listan algunas funciones y utilidades de los hilos. Todas estas funciones las tienes que importar desde el módulo threading:
current_thread(): esta función devuelve la referencia del hilo actual.main_thread(): esta otra función devuelve la referencia del hilo principal.active_count(): esta función devuelve el número de hilos activos del proceso actual.
Otra utilidad básica es la de poder enumerar todos los hilos para obtener información de los mismos. Se usa la función enumerate() del módulo threading. Por ejemplo, el siguiente programa muestra el nombre de todos los hilos activos:
import threading threads = threading.enumerate() for t in threads: print(t.name)
¿Cuándo usar hilos?
A estas alturas ya has desarrollado programas multiproceso y te has introducido en la programación multihilo. En Python, como te has dado cuenta, desarrollar programas multiproceso y multihilo es bastante parecido, así que, ahora, posiblemente, te estarás preguntando: ¿cuándo usar procesos y cuándo usar hilos? Te lo respondo aludiendo a la documentación oficial:
Threads are particularly useful when tasks are I/O bound, such as file operations or making network requests, where much of the time is spent waiting for external resources.
Es decir: deberías usar hilos para tareas en las que se realicen operaciones de Entrada/Salida que son tareas bloqueantes.
De esta manera, mientras un hilo está bloqueado esperando un recurso, el resto de hilos pueden seguir con sus tareas y, especialmente, el hilo principal, que debería permanecer siempre activo, sobre todo en aplicaciones con interfaces gráficas de usuario, ya que, como he explicado en clase, el hilo principal de las aplicaciones gráficas es el encargado de mantener "viva" la interfaz gráfica para que el usuario pueda interactuar con ella en todo momento.
Así pues, cuando tengas que realizar programas en los que se tengan que llevar a cabo tareas intensivas de CPU, ahí, en ese caso, deberías optar por usar procesos y explotar la concurrencia y el paralelismo por medio de la programación multiproceso.
Uso de ThreadPoolExecutor
Existe una manera más sencilla de dar comienzo a un conjunto de hilos por medio de una clase llamada ThreadPoolExecutor, que se encuentra en el módulo concurrent.futures de Python.
Esta clase facilita el desarrollo de programas multihilo como el que hemos visto anteriormente. De hecho, para entender cómo se usa un Pool Executor vamos a reescribir nuestro crawler:
import time from concurrent.futures import ThreadPoolExecutor def crawl(link, delay): print(f"crawl started for {link}") time.sleep(delay) print(f"crawl ended for {link}") if __name__ == "__main__": links = [ "https://python.org", "https://docs.python.org", "https://peps.python.org", ] with ThreadPoolExecutor(max_workers=2) as executor: for link in links: executor.submit(crawl, link, 3)
La forma más sencilla de usar un ThreadPoolExecutor es por medio de un Context Manager (with) de Python. De esta manera no nos tenemos que preocupar de manejar la finalización de los hilos como hacíamos en el ejemplo anterior con join().
El ThreadPoolExecutor necesita que le pasemos el número de workers (hilos) que se van a lanzar concurrentmente. En nuestro ejemplo hemos decidido que vamos a ejecutar los hilos de 2 en 2. Así, nunca habrán más de dos hilos ejecutándose en paralelo.
En este ejemplo, executor es el objeto de tipo ThreadPoolExecutor y, si leemos la documentación, hay varias maneras de lanzar los workers (hilos), una de ellas es por medio del método submit que recibe:
- Como primer argumento la función que cada worker (hilo) va a ejecutar.
- El resto de argumentos son, a su vez, los argumentos que se pasan a la función indicada anteriormente. En nuestro caso, la función
crawlnecesita dos argumentos: el enlace, en primer lugar, y el delay en segundo lugar.
Futuros en Python
Es posible que te haya llamado la atención que la clase ThreadPoolExecutor se encuentre en un módulo llamado concurrent.futures y no en el módulo threading. Esto se debe a que ThreadPoolExecutor está estrechamente vinculada a lo que, en Python, se conoce como Futuros.
Un futuro en Python es una característica del módulo concurrent.futures que permite realizar operaciones asíncronas y manejar el resultado de operaciones que pueden tardar en completarse, como tareas que implican I/O o computación intensiva. Es habitual usarse en programas multihilo.
Un futuro es un objeto que representa el resultado de una operación que puede completarse en el futuro. Permite que el programa siga ejecutándose mientras se espera el resultado.
El módulo concurrent.futures proporciona dos tipos principales de ejecutores que permiten trabajar con futuros, uno de los cuales es ThreadPoolExecutor.
Su funcionamiento es básico: cuando se envía una tarea a un executor, devuelve un objeto de tipo concurrent.futures.Future. Con este objeto puedes:
- Consultar su estado (si está en ejecución, completado o fallido).
- Obtener el resultado con el método
result(), el cual bloqueará el hilo hasta que la tarea esté completada.
Ejemplo con manejo de resultado
Vamos a reescribir el ejemplo anterior modificando la función crawl para que devuelva la página HTML que será recogida por medio del objeto concurrent.futures.Future.
import urllib.request from concurrent.futures import ThreadPoolExecutor, as_completed def crawl(link, timeout): with urllib.request.urlopen(link, timeout=timeout) as conn: return conn.read() if __name__ == "__main__": links = [ "https://python.org", "https://docs.python.org", "https://peps.python.org", ] with ThreadPoolExecutor(max_workers=2) as executor: futures = [] for link in links: future = executor.submit(crawl, link, 3) futures.append(future) for future in as_completed(futures): try: data = future.result() print(f"Página leída: {len(data)} bytes") except Exception as e: print(f"Excepción: {e}")